[AI] 누구나 쉽게, AI 모델 사용하는 방법
with python and huggingface
Intro
머신러닝 및 딥러닝 기술의 발전으로 AI 모델을 사용하는 것이 점점 더 일상화되어가고 있다. 이러한 인공지능 모델을 사용하려면 복잡한 모델 설계와 구현 작업을 거쳐야 하는 것이 일반적이다. 그러나 최근에는 Hugging Face와 같은 라이브러리들이 출시되면서 누구나 쉽게 인공지능 모델을 사용할 수 있게 되었다. 이번 포스팅에서는 python으로 AI 모델을 사용하는 방법과 Hugging Face를 활용하여 쉽게 pre-trained 모델을 사용하는 방법을 알아보자.
1. Hugging Face에서 모델 찾기
Hugging Face는 다양한 Pretrained 모델을 제공하며, 이를 쉽게 사용할 수 있도록 Transformers라는 라이브러리를 제공한다. 우선 Hugging Face에서 제공하는 모델을 살펴보고, 필요한 모델을 찾아보자.
1. Hugging Face 웹사이트 (https://huggingface.co/models) 에 접속
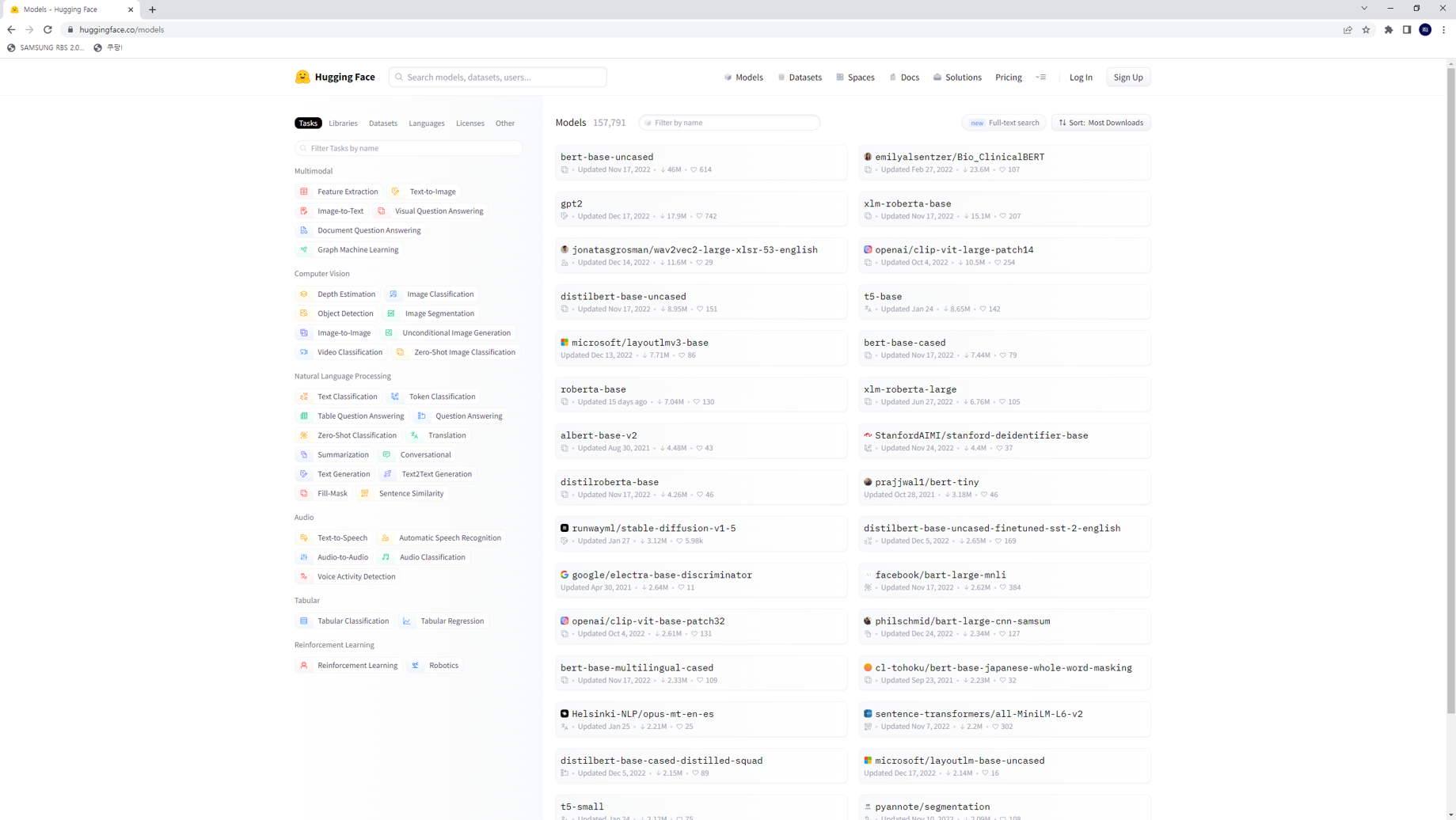
2. 원하는 모델을 검색. ex) GPT-2 모델을 사용하고자 한다면, ‘gpt-2’라는 키워드를 검색.
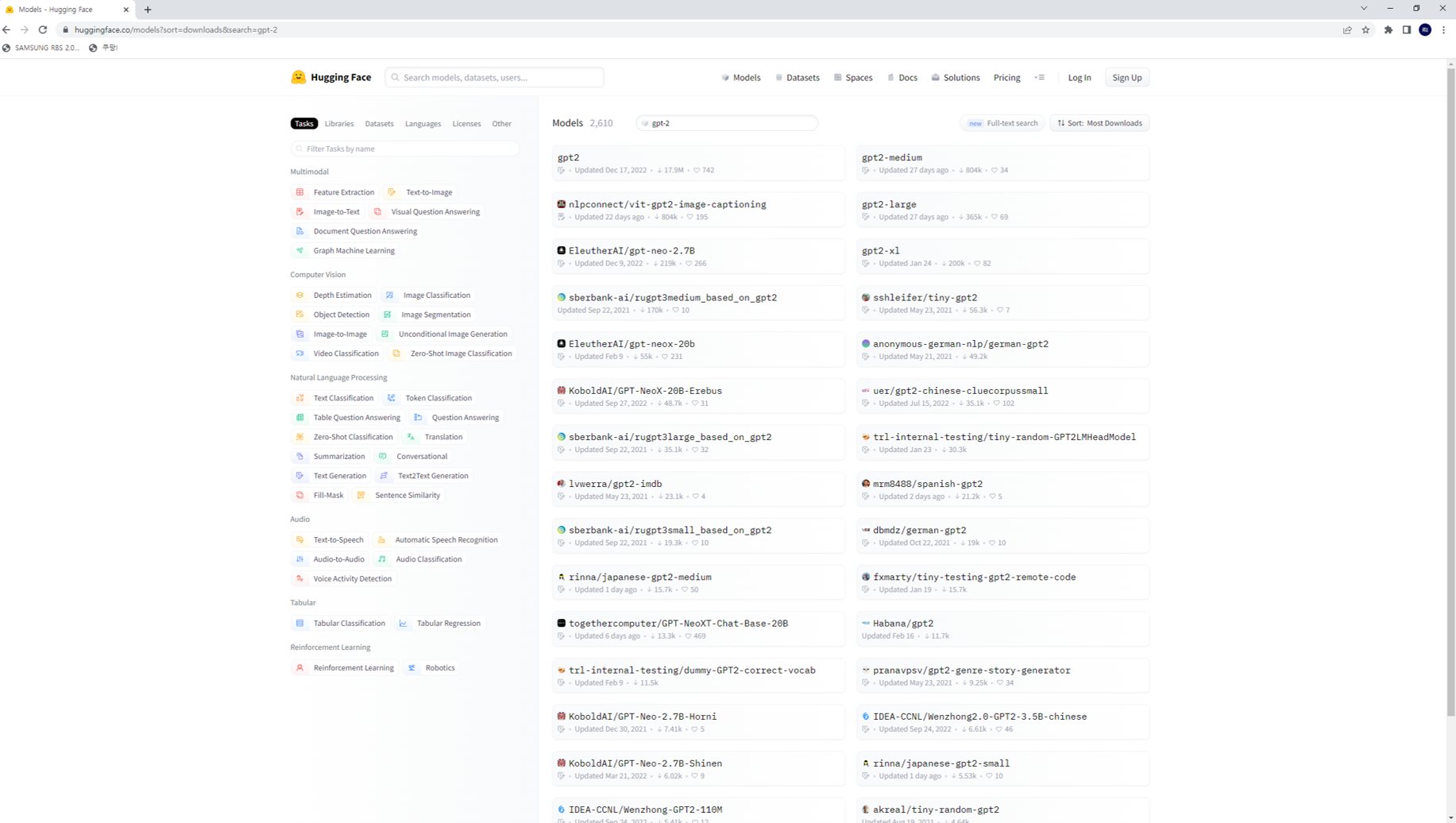
3. 검색 결과에서 필요한 모델을 선택하여 사용 방법을 확인한다.
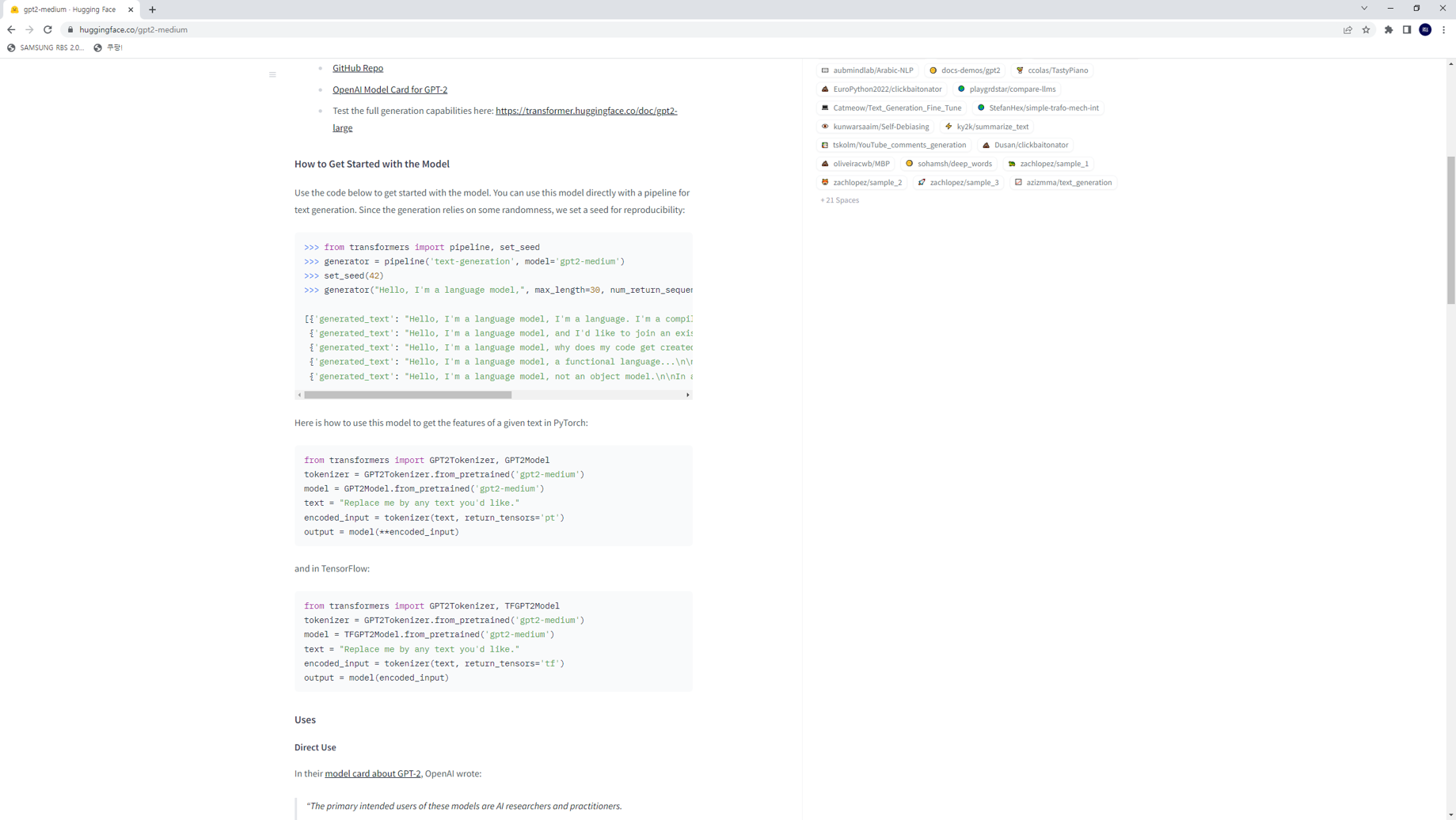
위 세가지 step만 알면 이제 어떤 모델이든 직접 사용해 볼 준비가 된 것이다.
2. Transformers 라이브러리 설치
Hugging Face에서 제공하는 Transformers 라이브러리를 설치하여 Pretrained 모델을 쉽게 사용할 수 있다. 다음 명령어를 터미널에서 실행하여 Transformers 라이브러리를 설치해보자.
pip install transformers
설치가 정상적으로 안될 경우 아래 Hugging Face github url을 참고
https://github.com/huggingface/transformers
3. Pre-trained 모델 사용하기
설치가 완료되면, 다음과 같은 코드를 사용하여 pre-trained 모델을 쉽게 사용할 수 있다.
from transformers import AutoTokenizer, AutoModelForCausalLM
# 모델 이름과 토크나이저 이름 지정
model_name = "gpt2-medium"
tokenizer_name = "gpt2"
# 모델과 토크나이저 불러오기
tokenizer = AutoTokenizer.from_pretrained(tokenizer_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# 입력 문장 설정
input_sentence = "The quick brown fox"
# 문장을 토큰화하고, 모델에 입력하기 위한 형식으로 변환
input_ids = tokenizer.encode(input_sentence, return_tensors='pt')
# 모델에 입력하여 출력 결과 생성
outputs = model.generate(input_ids)
# 출력 결과를 문자열 형태로 변환하여 출력
output_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(output_text)
위 코드에서는 AutoTokenizer와 AutoModelForCausalLM을 사용하여 tokenizer와 model을 불러왔다. 이후, 입력 문장을 토큰화하여 모델에 입력하기 위한 형식으로 변환한 뒤, model.generate() 함수를 사용하여 출력 결과를 생성한다. 마지막으로, tokenizer.decode() 함수를 사용하여 출력 결과를 문자열 형태로 변환하여 출력하면 된다.
위 예시에서 사용한 AutoModelForCausalLM 클래스는 Causal Language Modeling을 수행하는 모델이다. 이 외에도 Hugging Face에서는 다양한 Pretrained 모델을 제공하며, 각 모델의 특성에 따라 사용하는 클래스가 달라진다.
4. 추가 예시: sentiment analysis
이번에는 Hugging Face에서 제공하는 pre-trained 모델을 활용하여 간단한 감성 분석을 수행해보자.
from transformers import pipeline
# 감성 분석 파이프라인 생성
sentiment_pipeline = pipeline('sentiment-analysis', model='nlptown/bert-base-multilingual-uncased-sentiment')
# 입력 문장 설정
input_text = "I love this movie!"
# 감성 분석 수행
result = sentiment_pipeline(input_text)
# 결과 출력
print(result)
pipeline() 함수를 사용하여 감성 분석 파이프라인을 생성하고, sentiment-analysis 파이프라인과 nlptown/bert-base-multilingual-uncased-sentiment 모델을 사용하여 감성 분석을 수행하는 코드이다. 입력 문장을 input_text 변수에 설정하고, result 변수에 결과를 저장하면 된다.
마치며
이번 포스팅에서는 python으로 AI 모델을 쉽게 사용하는 방법과 Hugging Face를 활용하여 pre-trained 모델을 사용하는 방법에 대해 알아보았다.
위에서 알 수 있듯이, transformers를 활용하면 정말 간단하게는 이렇게 단 4줄로 ai 모델을 활용해 볼 수도 있다. 게다가 https://huggingface.co/models 에서 제공하는 모델들 중에는 license를 필요로하는 모델들도 있지만, open source로 된 모델들도 꽤나 있기 때문에 다양한 모델들을 사용해 볼 수 있고, 각 모델 별로 github에 소스가 있기 때문에 fine-tuning을 하는 것도 그렇게 어렵지 않다.
이제는 AI에 대한 지식이 크게 없어도 Hugging Face에서 제공하는 pre-trained 모델과 transformers를 활용해 누구나 간단하게 AI 모델을 이용한 서비스를 제공할 수 있다. AI 기술이 보다 쉽게 접근 가능해지면서, 다양한 분야에서 AI 기술의 활용이 더욱 증가할 것으로 기대된다 :)
Reference
- https://huggingface.co/models
https://github.com/huggingface/transformers